Fault Localization with Probabilistic Software Modeling: A New Approach
Fault localization remains a critical challenge in software development, as traditional techniques struggle with complex, multi-line errors and high false-positive rates. This article introduces Fault Localization via Probabilistic Software Modeling (FL-PSM), an approach that leverages probabilistic models to analyze software behavior dynamically and identify faults more accurately. By comparing runtime data against a probabilistic baseline, FL-PSM improves fault detection, enhances debugging efficiency, and reduces false positives. We explore its methodology, application to a real-world example, and its potential advantages over existing techniques.
The Problem with Traditional Fault Localization
Software development is a balancing act between innovation and reliability. While testing techniques help identify when something goes wrong, pinpointing where the issue resides remains a challenge. Traditional fault localization techniques, such as Spectrum-Based Fault Localization (SBFL), often struggle with complex software errors. Fault Localization via Probabilistic Software Modeling (FL-PSM), aims to tackle this challenge by leveraging probabilistic models to analyze software behavior and identify faults more accurately.
When software malfunctions, developers need to track down the root cause. This process, known as fault localization, involves analyzing the code and determining which part is responsible for the error. Existing approaches often rank statements by their likelihood of containing a fault, but they struggle with:
- Complex faults spanning multiple lines (76% of faults fall into this category)
- Errors caused by omitted statements (30% of faults)
- High false-positive rates, making debugging cumbersome
Introducing Probabilistic Software Modeling
Probabilistic Software Modeling (PSM) shifts the paradigm by modeling software as a network of Probabilistic Models (PMs), where each model represents a function or method in the program. These models learn from runtime behavior, capturing relationships between inputs and outputs. This allows FL-PSM to:
- Analyze code behavior dynamically using test-suite data or live execution traces
- Detect deviations from expected behavior by evaluating likelihood scores of runtime data
- Identify fault locations and their impact on dependent code elements
How FL-PSM Works
FL-PSM builds upon PSM by applying statistical inference to detect faults. The method works as follows:
- Build a Baseline Model: FL-PSM generates a null model from correctly functioning software, capturing expected behavior.
- Introduce New Execution Data: When an error occurs, the system collects new runtime traces.
- Compare Data Using Likelihood Scores: FL-PSM evaluates whether the new execution data significantly diverges from the expected model.
- Pinpoint Fault Locations: If a method's behavior is statistically different, it is flagged as a potential fault location.
By controlling the false-positive rate, FL-PSM improves precision, reducing wasted effort on investigating non-faulty code.
A Practical Example: The Nutrition Advisor
To illustrate FL-PSM in action, consider a Nutrition Advisor application that calculates Body Mass Index (BMI) based on height and weight. Suppose two errors are introduced:
- Regression Fault: A typo in the
Personconstructor mistakenly assigns a negative weight. - Integration Fault: Two teams use different units (meters vs. inches) for BMI calculation.
FL-PSM detects these issues by analyzing the likelihood distributions of affected methods. It visualizes discrepancies in runtime behavior, helping developers quickly isolate faulty code sections.
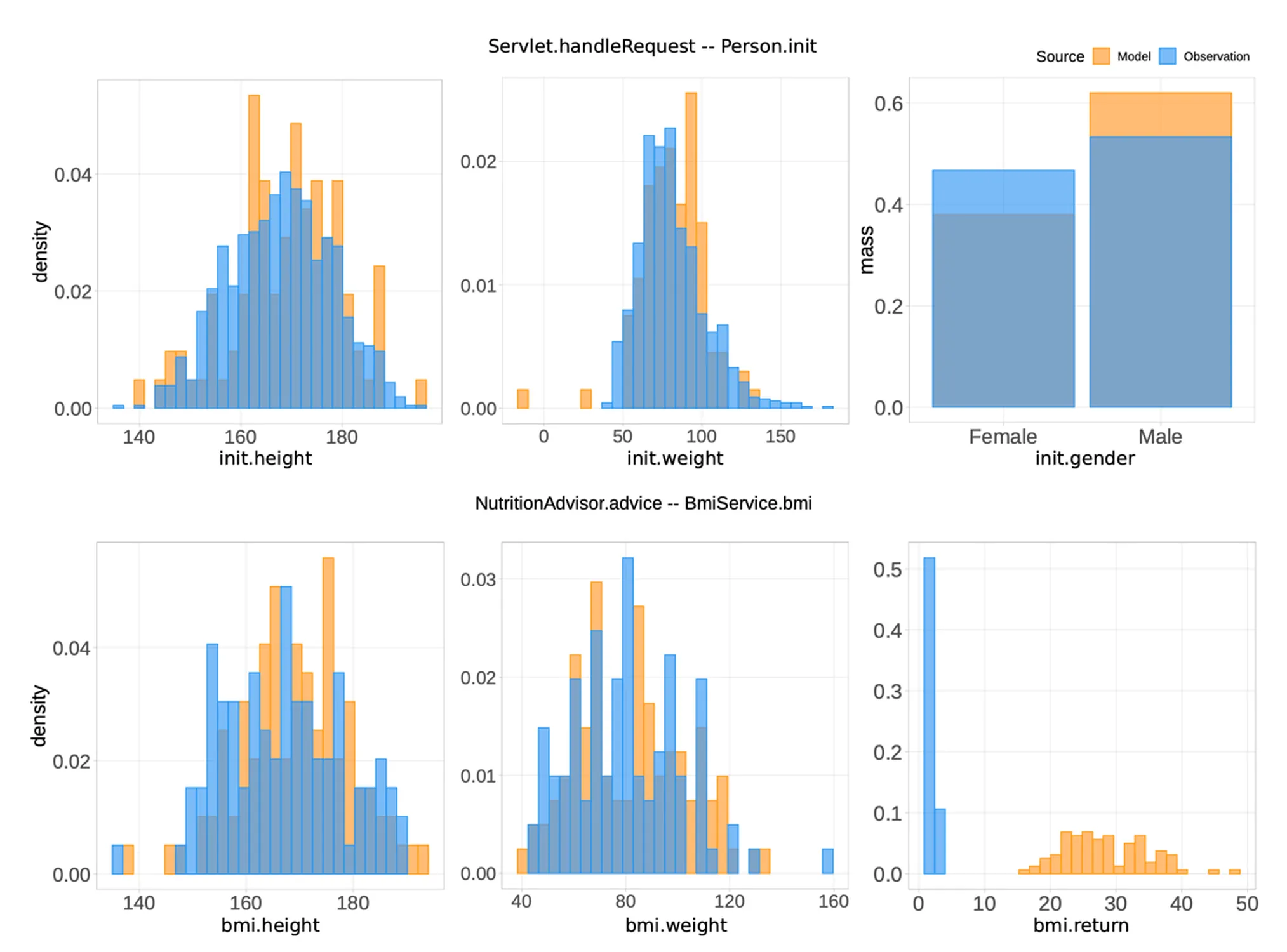
Why FL-PSM is a Game-Changer
Unlike traditional fault localization techniques, FL-PSM provides:
- Better fault visibility: Visualization of error chains helps in debugging.
- More accurate fault detection: Probabilistic modeling accounts for dependencies across methods.
- Lower false-positive rates: Significance testing ensures only genuine faults are flagged.
Looking Ahead
FL-PSM presents a promising shift in debugging methodology, but challenges remain. Future research will explore how to handle multiple simultaneous faults and refine fault visualization techniques. As software complexity grows, techniques like FL-PSM will be crucial in improving software reliability and reducing debugging time.
By integrating probabilistic models into fault localization, FL-PSM bridges the gap between test results and actionable debugging insights—bringing us one step closer to error-free software.
References and images available in the original research paper.
arXiv